这本书Deep Learning来自Ian Goodfellow,Yoshua Bengio和Aaron Courville,免费开源,且有github中文版,是一本不可多得的机器学习教材,在这里留下学习笔记以勉励自己。
工具,机器,人工智能
人类之所以为人类,是因为突破了自身的体力、智力极限(不知何时能突破生命极限),从古至今,人工智能都是主题不变的幻想,然而真正实现的路途可谓任重道远。计算机的体系结构决定了其能够较好地解决形式化语言所描述的问题,然而人类的智力不仅仅由逻辑组成,“直觉”一直是不可描述之物(圣斗士还有小宇宙呢…),故而在早期的案例中,计算机能够在诸如棋类的游戏中成功打败人类,却无法很好地进行图像、语音识别,即人工智能的挑战之一是如何将非形式化知识转变为形式化规则。
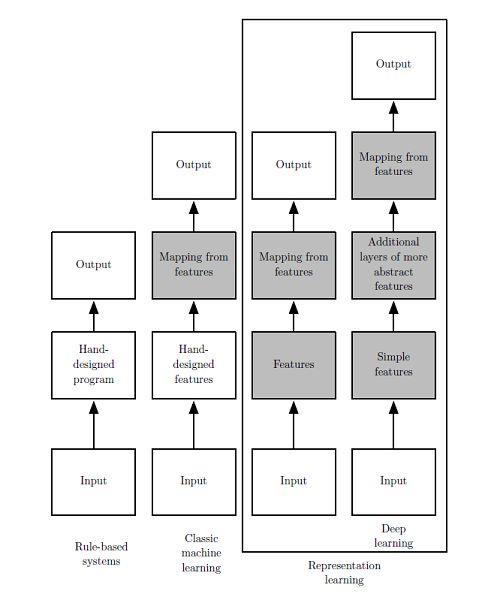
曾有人工智能项目试图将大众知识“硬编码”,构建数据库,如Cyc项目,然而对于知识的描述本身在逻辑上是不完备的,也是难以完成的,人工智能需要具备自己获取知识的能力,需要具备从原始数据中提取特定模式的能力,即机器学习(machine learning)。个人倾向于将理想的机器学习分为两步,前一步是将原始数据抽提出特征,后一步是通过特征建模得出结论,这也类似于人类学习的过程,人类大多是先观察再总结,从普适中观察特性,从特例中总结规律。
表示学习,深度学习
一些简单的算法如逻辑回归(logistics regression)、朴素贝叶斯(naive Bayes)等在机器学习领域均取得了较好的效果,也为相关算法的不断深入研究打下了基础。不过这些算法的局限性在于依旧需要“人为的”从原始数据中提取特定模式,即需要原始数据的表示(representation)。比如利用逻辑回归判断产妇是否适合剖腹产时,AI系统不会直接检查患者,而是需要医生告诉系统几条相关的信息,诸如是否存在子宫疤痕等,这些信息被称为特征。逻辑回归通过学习特征与结果之间的关联性而给出结论,但如果将病人的MRI扫描直接作为逻辑回归的输入,而不是医生的正式报告,它将无法作出有用的预测。所以对于早期的系统来说,人为抽提特征之难暗中掣肘。
解决方法之一是利用机器学习发掘数据信息本身,而不是仅仅将表示映射到结果,这种方法被称为表示学习(representation learning)。典型的例子如自编码器(autoencoder),能够自主训练输入数据,转换为不同的表示特征。
为达到识别、判断数据的目的,重点往往在于分离出变差因素(factors of variation)。这些因素有的客观存在,有的却是人类的主观意识,过于概念化、抽象化,比如口音,影响口音的因素太多,如何抽提出关键性的表示特征?而且这些特征可能是多层次的、相互关联、动态变化的。传统的表示学习算法已无法解决,这就引入了深度学习(deep learning)的概念,深度学习通过将一系列较简单的表示进行多层次组合来反映复杂表示,解决了表示学习中的核心问题。如多层感知机(multilayer perceptron,MLP)仅仅是一个将一组输入值映射到输出值的数学函数,而该函数由许多较为简单的函数复合而成,不同数学函数的每一次应用都为输入提供了新的表示。
 表示学习、深度学习解放了数据收集者,人们只需提供大量相关的、可能相关的、甚至看上去不怎么相关的数据信息,算法便能从中抽提出重要的特征、识别特征之间的关联性等。
表示学习、深度学习解放了数据收集者,人们只需提供大量相关的、可能相关的、甚至看上去不怎么相关的数据信息,算法便能从中抽提出重要的特征、识别特征之间的关联性等。
神经网络
深度学习其实并不是一个新兴领域,只不过前些年比较冷罢了。一般会认为深度学习经历了三次发展浪潮:20世纪40年代到60年代其雏形出现在控制论(cybernetics)中,20世纪80年代到90年代表现为联结主义(connectionism),直到2006年才真正以深度学习之名复兴(这恐怕也得益于计算机硬件水平的突飞猛进)。
在如今一提到深度学习,往往会跟神经网络联系起来,需要注意的是,深度学习包括但不局限于神经网络,但神经网络绝对是当今最成功的模型之一。从概念上,神经系统是智能行为的直接例子,因而模拟大脑一方面可以为AI系统带来计算原理的可能性,一方面也可以帮助生物学家以数学的方式来理解神经系统。
从神经科学的角度出发,建立一个简单的线性模型,其实就是一组n个输入\(x_{1},...,x_{n}\)得到一个输出\(y\),对于每个输入需要学习出一组权重\(w_{1},...,w_{n}\),即\(f(x,w)=x_{1}w_{1}+...+x_{n}w_{n}\)。这即是控制论。早期模型如McCulloch-Pitts 神经元,到了50年代,感知机(perceptron)成为第一个根据数据输入来学习特征权重的模型,简单的算法却大大影响了神经网络的发展,后来的随机梯度下降(stochastic gradient descent)等至今仍是深度学习的主要训练算法。线性模型简单实用而得到了广泛使用,不过其局限性也很多,著名的如无法学习异或函数(XOR,相同为0,不同为1)。这导致了神经网络热潮的第一次衰退。
由于大脑过于庞大的信息系统和背后的生物学机制难以理解,神经科学始终没有大尺度上的突破,也使得计算机学家不再执着于严格模拟大脑,更多地只是借鉴其思想。目前大多数神经网络是基于被称为整流线性单元(rectified linear unit)的神经单元模型。80年代的第二次浪潮很大程度上关注的是将大量简单的计算单元连接在一起时的并行计算、分布处理等,其中一个重要概念是分布式表示(distributed representation),即系统的每一个输入都应该由多个特征表示,同时每一个特征都应该参与到多个可能输入的表示中。这段时期中的另一个成就是反向传播算法(back propagation),至今仍是训练深度模型的主导方法之一。有些时候,研究热潮并不能直接转换为投资回报,加上同时期有核方法、图模型等的亮眼表现,神经网络热潮面临第二次衰退,并一直持续到2006年左右。
随着计算机硬件能力不断提高、训练算法不断突破,2006年后迎来了神经网络研究的第三次浪潮,著名的有Geoffrey Hinton为深度信念网络使用的贪婪逐层预训练策略,这些突破也让深度学习和神经网络紧密联系并普及开来。近年来,计算机应用及网络深入到工业的各个行业、生活的各方各面,使得数据量急剧增加,“大数据”时代使得机器学习更加容易。一个粗略的经验法则是,监督深度学习算法在每类给定约5000个标注样本的情况下就能够达到可以接受的性能,当至少有1000万个标注样本的数据集用于训练时,它将达到或超过人类表现。
挑战和机遇
机器学习为工业、商业、科学做出了巨大贡献,对于我们来说,如何利用深度学习、神经网络等为庞大复杂的生物学系统的研究带来新的突破,同时又如何深入研究神经科学、基因组学等领域为AI系统的研发引入新的思想,将是生物信息作为交叉学科的挑战和机遇。

