抽丝剥茧,去粗取精…
要降维,不要降信息量
测序技术带来了基因组数据爆炸式的增长,每个样本会观测到N个指标,带来N维矩阵,庞大的信息量往往让生物学家无所适从。科学探索追求一个最简单的准则:所见即所得。如何将N维数据更好地呈现出来,是生物信息学家迫切需要做到的。于是乎,“降维”几乎成了数据预处理的必备步骤,将高维数据映射至二维或者三维图像中,从而更好地分辨各个样本,为科学假设提供线索。
PCA是一种经典的降维算法,通过正交变换,将可能存在线性相关的变量映射为线性不相关的变量。而其中,为了保证最大限度地保留原始数据中的信息,PCA所找到的正交基,要求映射后的数据方差最大化(方差代表着数据的差异,也就是隐含在数据中的信息),或者误差最小化(这两种理解在最终数学形式表达中是一致的)。为此,我们首先计算原始数据的协方差矩阵,再计算该矩阵的特征向量和特征值,特征值即表征了该特征向量的“贡献”。
目的是降维
降维除了达到方便可视化的目的之外,还能够减少存储、降低计算、用于特征提取等,因而是数据处理的重要研究方法。关于降维的算法有很多,下图是从网上转来的,总结得很好:
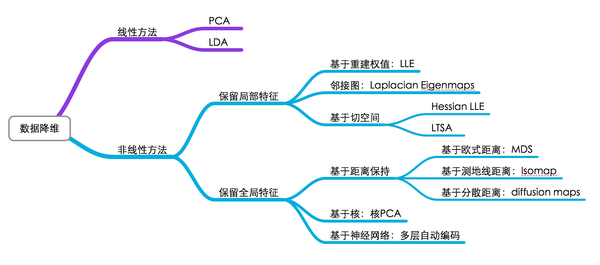 其中少了关于t-SNE的介绍,这是近年比较火的一个算法,在很多数据集上都有优异表现。
其中少了关于t-SNE的介绍,这是近年比较火的一个算法,在很多数据集上都有优异表现。

